1. 业务场景
主要考虑两个因素:
-
纯粹的数据量角度:
- 单表数据量过大已经影响查询性能(查看当前数据量)
- 数据量增长迅速,防患于未然(查看近一月数据量增长情况,对未来做出预期)
我们目前存在一个数据表1600w+数据,月增长200w左右。
-
客户实际感知的业务响应速度带来的直观用户体验影响
我们线上这个千万级的表查询速度已经5s+
2. 方案
2.1. 分表方式
预算这里已经单独使用一个MySQL实例,拥有不用与其他服务共享的,完全的CPU和磁盘IO性能,理论上性能够用,无需再做分库处理。
大多数场景依然还是单表数据量大,扫描行过多,增加了不必要的CPU负担。
水平分表,减少单表扫描行数,应该是较为简单快速的提升性能的一个方式。同时由于单表数据量变小,后续执行DDL时,也能更迅速。
因此使用水平分表。
2.2. 分表算法与分片键的选择。
分表时必须将“同一个客户”的数据落到一个表中,避免触发全表路由,不符预期。
**作为SaaS业务,我们采用企业的订阅号(企业编码)字段作为分片键。**对“同一个客户”的业务理解是字符串类型的企业编码相同的数据,这个字段也是一个表中的字段。
这里采用简单的哈希取模的方式,即:
Math.abs(企业编码.hashCode() % table_number)
缺点:
- 每家客户的数据量不一样,可能出现几个分表的“数据倾斜”的问题。
优点:
- 简单易实现,能够保证同一客户数据落到一个表中的业务预期。
- 通过一致性哈希算法来实现,后期扩容影响范围小,减少业务影响
后续优化方向上可以考虑单独pick出一些数据量大的企业,路由到单独的表中。
根据一致性hash算法,table_number我们需要约定一个固定的值,也就是一致性哈希环中的最大允许数量,使用2的幂数,因此可以用位运算取代模运算提高性能(参考HashMap的容量计算逻辑):
Math.abs(企业编码.hashCode() & (table_number - 1))
2.3. 分表数量
分表的数量上,以3年作为一个业务展望时间:
- 4500w数据 → 300w一张表 → 15张表 → 取2的4次方 → 16张表 → 表的序号从0到15
一致性hash环的数量,扩大2个量级,取2的6次方64,应该已经绰绰有余了,因此我们有了一个具体的分表算法来计算这个表序号:
int temp = Math.abs(企业编码.hashCode() & (64 - 1));
return temp / (64 / 16);
// ==> 进一步优化
return (Math.abs(企业编码.hashCode() & 63)) / 4;
后期假设第0张表数据量过多,我们需要二次分表第0张表扩容,我们假设增加一个序号为16的分表,只需要对表0做一次数据迁移即可,其他表按照一致性hash算法,不会发生分表变化。分表算法修改为:
int hashMod = Math.abs(企业编码.hashCode() & 63;
int temp = hashMod / 4;
if (0 == temp) {
return hashMod / 2 == 0 ? 0 : 16;
} else {
return temp;
}
如果序号为2的幂数,这里的算法会更简单,也是更标准的一致性hash算法,不过相应的影响的表数量也会更多,不做展开。
2.4. 迁移数据
2.4.1. 数据迁移技术选型
水平分表本质上是将原来一个表的数据按照分表算法将数据分配到n个分表中,因此存在数据迁移问题,即原表→若干分表
-
阿里云DTS工具(开源版Canal)
由于需要支持分表算法,一个思路是在MySQL中实现一个Java的String#hashCode方法,然后在迁移数据过程中对数据进行清洗,过滤符合当前分表算法的数据进入指定分表。
但是很遗憾,DTS工具商业版暂不支持该功能,后续Canal可能可以通过代码的方式支持,这一块待完善。
-
阿里云Dataworks工具(开源版DataX)
这个工具本质是一个大数据治理平台,支持自定义函数(可以用Java语言写UDF),能够满足需求。
选型上,只有Dataworks能够完成需求,下文说明如何通过阿里云Dataworks工具完成数据迁移。
-
首先,需要将上文的分表算法用Java语言描述,需要开发一个【UDF】发布到阿里云的Dataworks的函数上:
-
我这里使用的是Function Studio的方式发布上去的,代码参考:
package com.alibaba.dataworks.udf; import com.aliyun.odps.udf.UDF; public class DataTransfer extends UDF { public Integer evaluate(String s) { int hash = s.hashCode(); return (Math.abs(hash & 63)) / 4; } }需要注意的是,Function Studio后续不再维护,阿里云官方鼓励自己上传jar的方式:

-
-
用【ODPS SQL】创建两个ODPS表,一个用来从源库同步全量数据,一个用来存储分表数据,这里的数据是写文件的,速度很快:
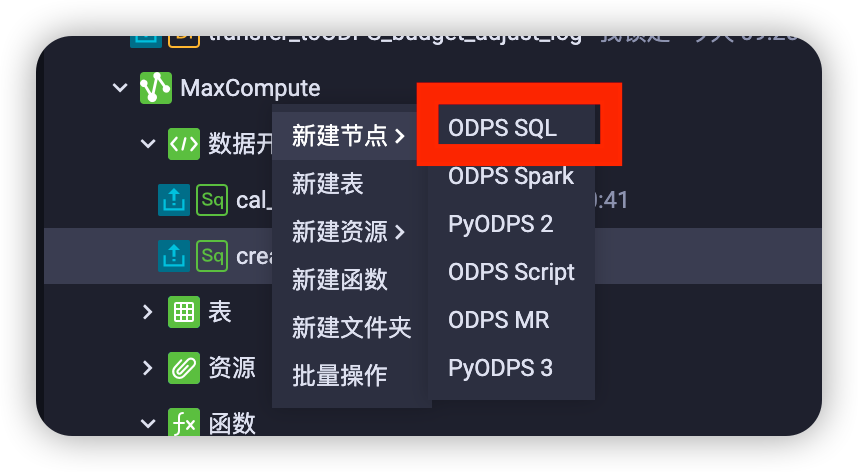
DROP TABLE IF EXISTS log_odps; CREATE TABLE IF NOT EXISTS log_odps( ... ) COMMENT '' PARTITIONED BY (pt STRING) lifecycle 36500; DROP TABLE IF EXISTS log_odps_sharding; CREATE TABLE IF NOT EXISTS log_odps_sharding( ... ) COMMENT '' PARTITIONED BY (pt STRING) lifecycle 36500; -
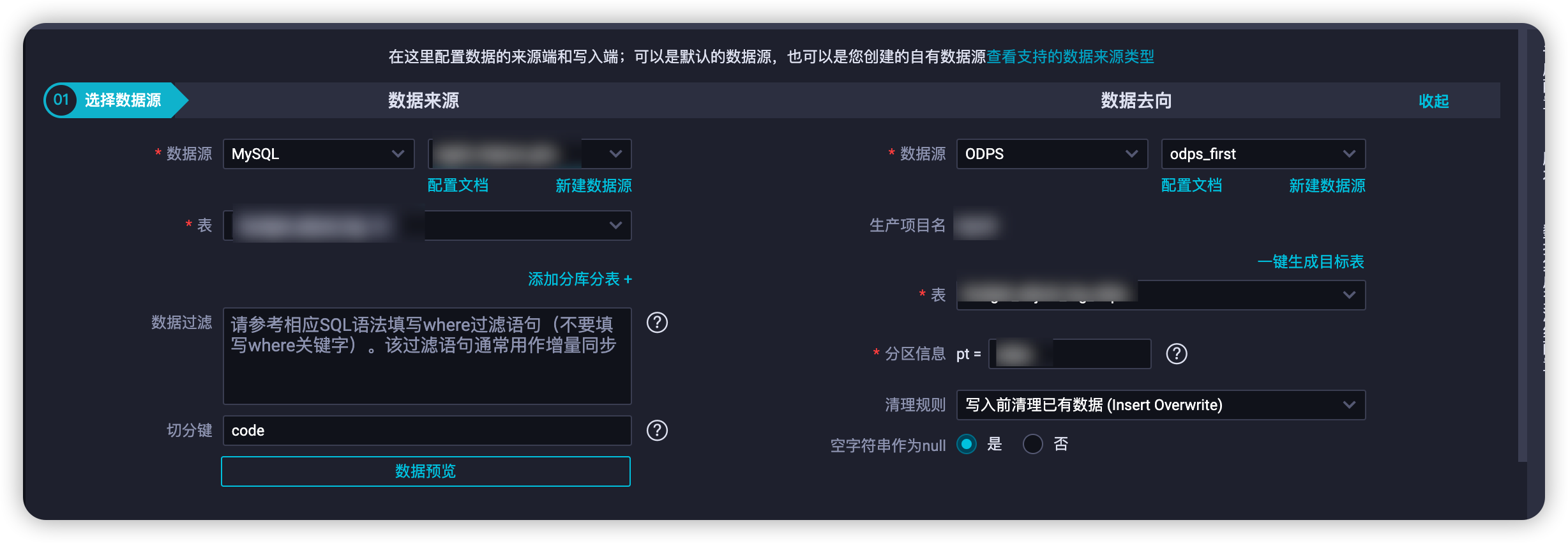
用【数据集成】从MySQL数据源同步数据到ODPS中,需要注意这里的清理规则建议选择“Insert Overwrite”,这样后续可以重复执行不需要清理ODPS数据,分区可以随便填写一个字符串:
-
同步到ODPS数据后,用【ODPS SQL】,可以用“create … as …”语法,将ODPS中的数据同步到一个新表中,每个分表为一个分区:
set odps.sql.allow.fullscan=true; insert overwrite table log_odps_sharding partition(pt) select `(pt)?+.+`, DataTransfer(企业编码) as pt from log_odps;set odps.sql.allow.fullscan=true开启全表扫描。也可以指定下面的select语句的分区,否则需要开启全表扫描(只有一个分区,无意义)insert overwrite写数据前清理数据。(pt)?+.+除了pt字段以外的字段(Hive SQL这里分区字段会作为SELECT *的一列返回,因此需要排除)- DataTransfer为我们定义的UDF函数,这里我们直接调用函数的结果作为log_odps_sharding的分区字段
- 至此,我们的log_odps数据会分布在log_odps_sharding对各个分区中,分区字段则为分表的表序号。
-
用【数据集成】将ODPS数据写回原数据源。
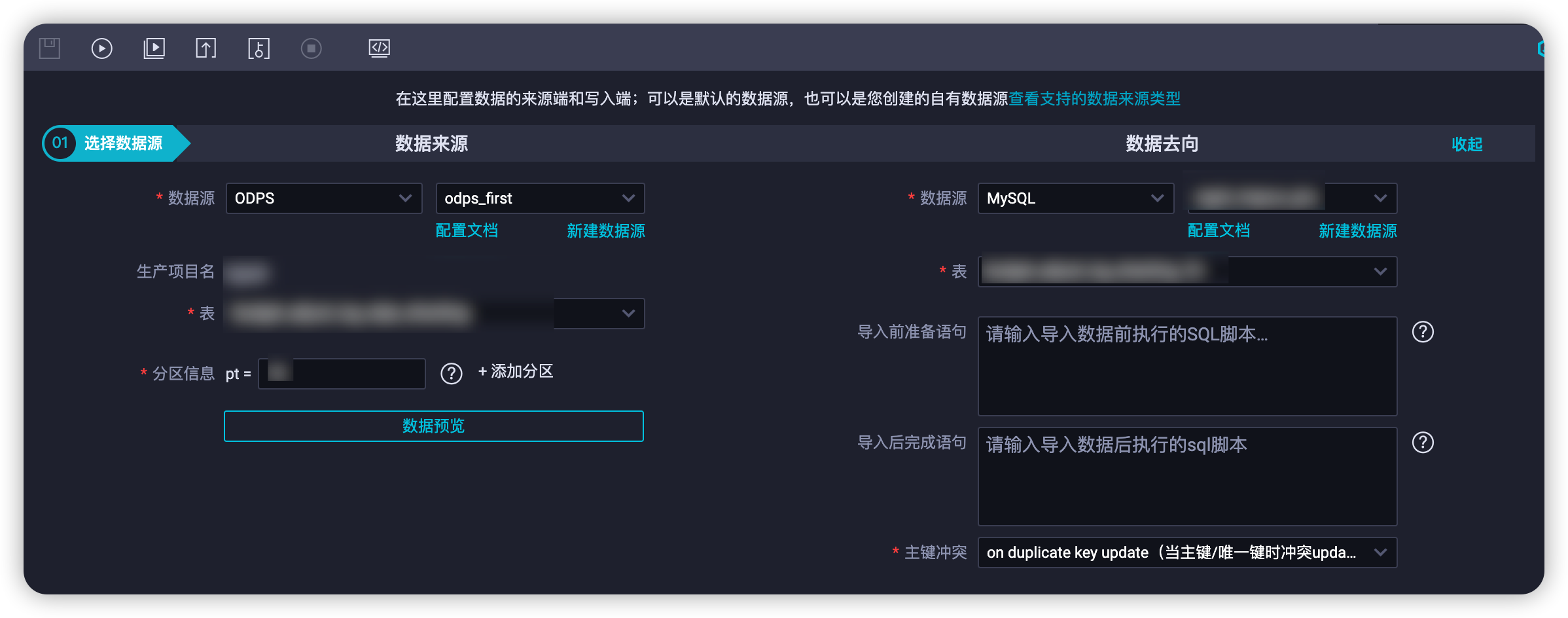
- 这里的pt值,按照上面的分表算法,我这里直接写1,2,3之类的分表序号即可
- 主键冲突策略选择“on duplicate key update”策略,这样可以多次执行实行不停机迁移(下文说明)
2.4.2. 不停机迁移
不停机迁移的方案基本上是两个步骤:
- 全量数据迁移(数据量大,比较慢,需要提前执行,可以在发版前执行)
- 增量数据同步(数据量小,比较快,可以在发版后执行)
需要注意,这里增量数据同步追平全量数据时:
- 会有一段时间的数据不一致的。这个如果有很高的要求可以尝试“实时计算”同步的方案,尽可能缩小增量数据同步时间也就缩小了数据不一致的时间区间(dataworks中有【实时同步】选项)
- 最终一致性。当增量数据同步完成,追平全量数据的时刻,数据是一致的。
不停机迁移这里由于Dataworks是即时读取数据源数据,而不是像DTS那样可以感知到binlog,因此需要保证数据的修改有“标记”:
- 数据行上要有逻辑删字段。
- 数据行上要有代表修改时间的字段。
在Dataworks上的具体实践:
-
全量数据迁移:按照上文流程走即可
-
增量数据迁移:
- 在新发布的分表代码中,需要对数据进行**“双写”,即:新写入/修改的数据,在对对应分表发生操作的同时,也对原始表进行一次同样的操作,二者需要保证原子性。(如果是同数据库,可以使用本地事务),在此基础上,我们就可以确定:原数据表一定是最新的数据。**
- 在上文迁移方案中的第三步“用【数据集成】从MySQL数据源同步数据到ODPS中”过程中,我们可以指定只同步修改时间大于“全量数据同步开始的时间点”的数据
- 其余流程不变,再次执行即可。
由于我们遇到相同数据时选择了“on duplicate key update”策略,Dataworks会帮助我们update数据。由于我们加入了逻辑删字段,即时数据发生了删除,Dataworks也会理解为一次update,因此不会发生数据没有正常删除的问题。
2.5. 异常回滚
由于上述不停机迁移过程中采用了“双写”,因此这里一旦发生异常,只需要切回异常前代码与配置即可。
2.6. 框架选择
市面上分表的框架还是比较多的,比如kingshard**,**ShardingSphere,Mycat等。
这次选型不严谨选用ShardingSphere下的ShardingSphere,主要出于以下考虑:
- 社区活跃度上,ShardingSphere的社区活跃度很高。
- ShardingSphere-JDBC无需额外部署服务,JAR包方式接入。
- 隔壁小伙伴有使用的ShardingSphere经验,技术栈一致,减少维护和学习成本。
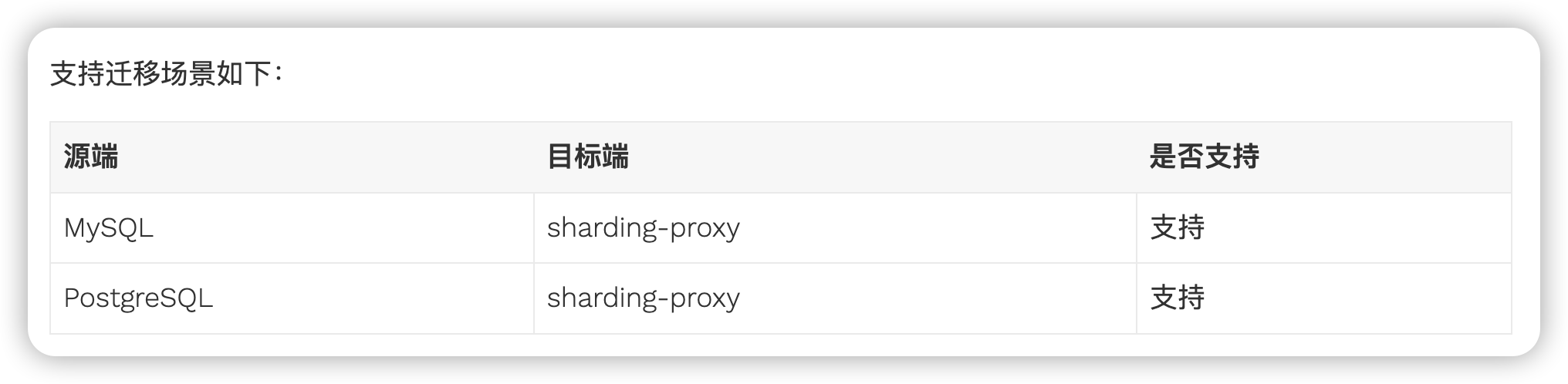
ShardingSphere下又有几个产品,ShardingSphere-JDBC,Sharding-Proxy,Sharding-Sidecar(规划中):

这里选择了ShardingSphere-JDBC,主要考虑ShardingSphere-JDBC运维成本比较低,无需部署额外的中心化服务,去中心化,分表的配置主动权在开发这里。
当然ShardingSphere-JDBC也会存在一些缺点:
-
不支持弹性伸缩,每次调整分片算法后,需要将数据手动迁移到各分片上。
4.1.0版本之后,提供了Sharding-Scaling方案解决弹性伸缩问题,只支持Sharding-Proxy方案。
2.7. ShardingSphere-JDBC使用流程
Maven坐标(SpringBoot starter方式接入):
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>latest.version</version>
</dependency>
配置参考:
# sharding-jdbc
# datasource config
spring.shardingsphere.datasource.names = ds0
spring.shardingsphere.datasource.ds0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.url = jdbc:mysql:xxx
spring.shardingsphere.datasource.ds0.username = xxx
spring.shardingsphere.datasource.ds0.password = xxx
# sharding table config
spring.shardingsphere.sharding.tables.[table_name].actual-data-nodes = ${['ds0']}.[table_name]_$->{0..15}
spring.shardingsphere.sharding.tables.[table_name].table-strategy.standard.sharding-column = [shard_key]
spring.shardingsphere.sharding.tables.[table_name].table-strategy.standard.precise-algorithm-class-name = com.maycur.budget.config.sharding.MaycurPreciseShardingAlgorithm
# show sql
spring.shardingsphere.props.sql.show = true
- spring.shardingsphere.datasource.xx 指定数据源配置
- spring.shardingsphere.sharding.tables.xx 指定分表配置
- spring.shardingsphere.props.sql.show 展示实际路由的分表的SQL
这里分片的策略是自己写了一个类:
import java.util.Collection;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
/**
* Sharding algorithm.
*
* @author <a href="mailto:masaiqi.com@gmail.com">masaiqi</a>
* @date 2022/7/18 17:39
*/
public class MaycurPreciseShardingAlgorithm implements PreciseShardingAlgorithm<String> {
@Override
public String doSharding(Collection<String> collection,
PreciseShardingValue<String> preciseShardingValue) {
String value = preciseShardingValue.getValue();
int shardingKey = getShardingKey(value);
return collection.toArray()[shardingKey].toString();
}
private int getShardingKey(String originKey) {
return Math.abs(originKey.hashCode() & 63) / 4;
}
}
需要注意的是,这个类无需交给Spring IOC管理,Sharding-JDBC会负责实例化对象:
public static <T extends ShardingAlgorithm> T newInstance(final String shardingAlgorithmClassName, final Class<T> superShardingAlgorithmClass) {
Class<?> result = Class.forName(shardingAlgorithmClassName);
if (!superShardingAlgorithmClass.isAssignableFrom(result)) {
throw new ShardingSphereException("Class %s should be implement %s", shardingAlgorithmClassName, superShardingAlgorithmClass.getName());
}
return (T) result.newInstance();
}
备选方案:分片的策略也可以使用ShardingSphere的行表达式,不过分片key为字符串时,groovy不允许直接取模,需要转换为字符串,再加上没有Java中的String#hashcode方法,比较复杂。
spring.shardingsphere.sharding.tables.[tablename].table-strategy.inline.algorithm-expression=[groovy expression]
Done!启动运行。